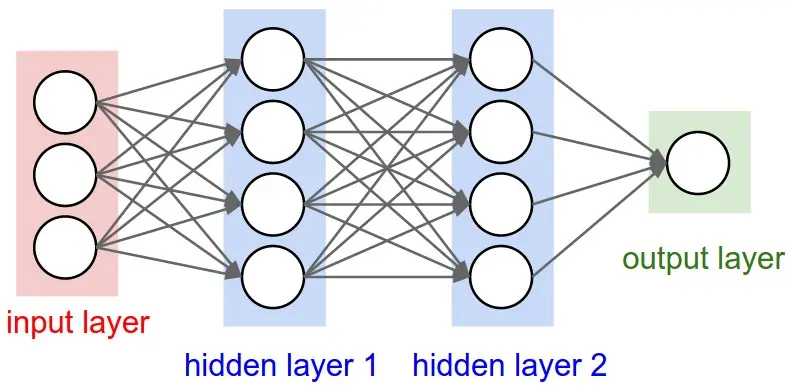
卷积神经网络-CNN
何谓卷积
单凭卷积这一个称号大概可以吓死一半的普通老百姓了。一开始接触卷积网络的时候,我就差点成了那一半的老百姓,幸好我命大,最终挺过来了。卷积,只依稀记得当年大学概率论稍有提过这样的名词,那时不愿深究,现在胆子大了,没事,维基搞起,卷积定义为:
好吧,这货长得这么奇怪,根本无法直觉地知道此货的作用,难怪一般人受不了。这还是是卷积一维连续的情况,但是我们的图片天生是二维的,而且计算机也只能处理离散的情况,所以这里我们的卷积应该是这样:
去掉了积分,现在友好一点。然而该一头雾水还是会一头雾水的,Ufldl的一张图片,一图胜万语啊,且看:
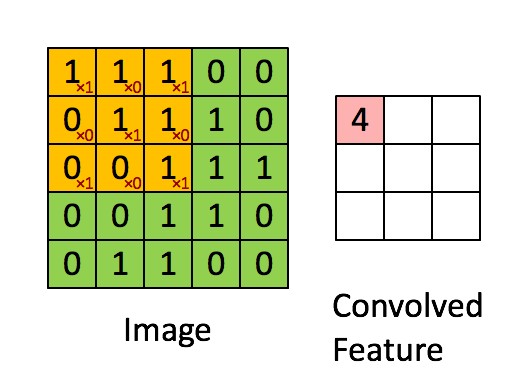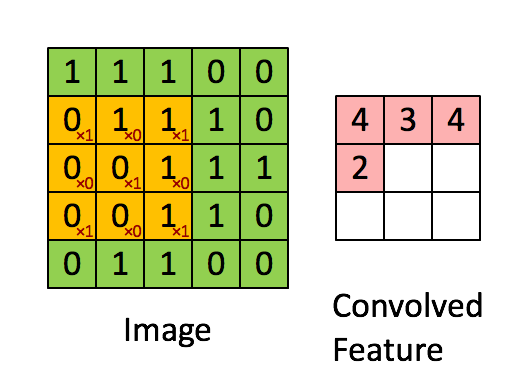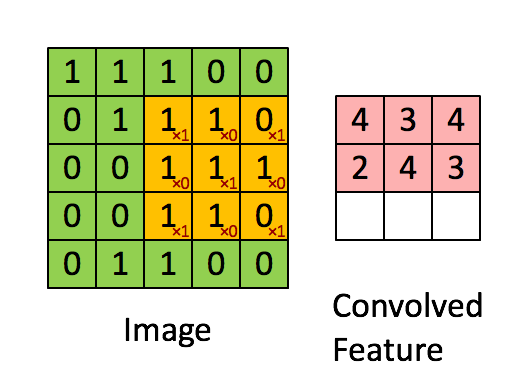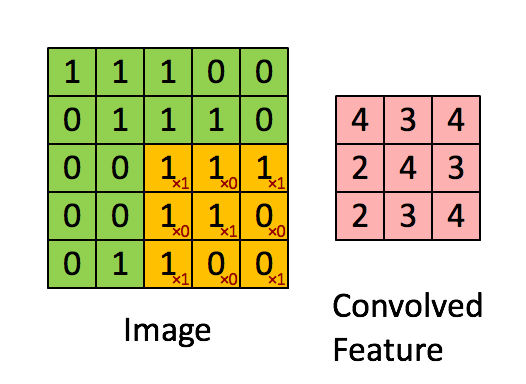
图中,我们有一张图片Image,大小是5X5,而经过卷积后,产生的卷积特征(图右),我们记为h,其大小是3X3,那个一直在移动的橘色方块术语比较多,有filter,kernel(卷积核)等等,我们就以kernel称呼吧,其大小为3X3。现在,我们可以和公式对应对应:
原始图片:
f = \left[ \matrix{ {1,1,1,0,0} \\{0,1,1,1,0} \\{0,0,1,1,1} \\{0,0,1,1,0} \\{0,1,1,0,0} }\right] 卷积核:
k = \left[ \matrix { {1,0,1} \\{0,1,0} \\{1,0,1} }\right] 卷积后的特征:
h =\left[\matrix{ {4,3,4} \\{2,4,3} \\{2,3,4}} \right]注意,我们的目的是要求取卷积后的特征,那么将我们的卷积公式代入这个例子中,可以得到:
python代码:
width = 3 |
这样计算的目的是什么呢,这么奇怪的计算方式,到底对于以后的识别有什么帮助呢?我们来看看卷积到底带给我们什么了,且看Coursera上海交通大学医学图像处理课程中卷积(因为图片是黑白的,其卷积过程完全由上面的几行代码即可实现)的几个例子:
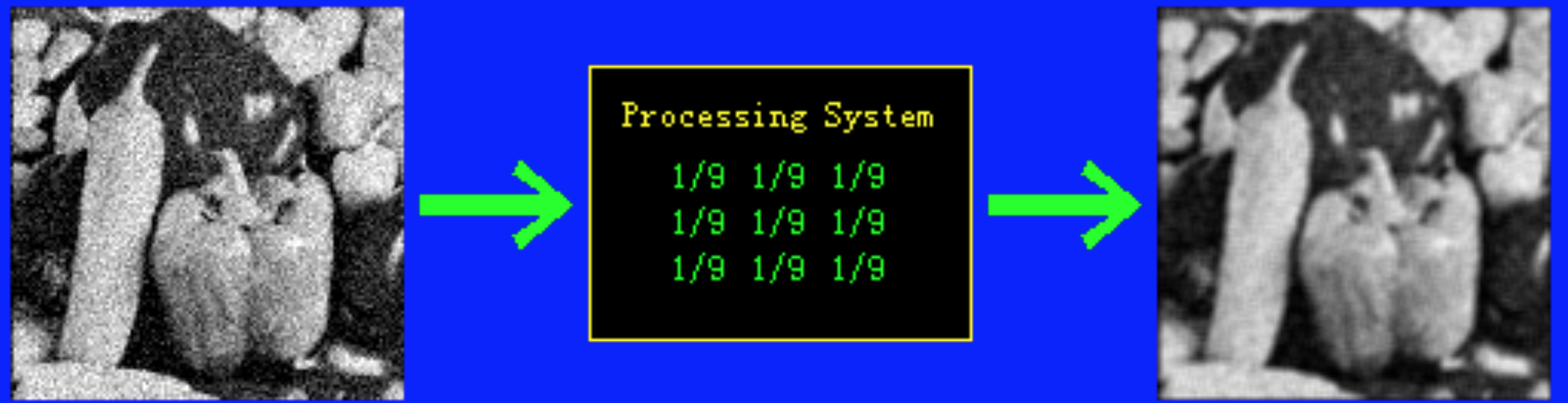
看到了吧,原始图片经过中间特殊的卷积核处理之后,可以得到图片的边缘,或者可以去除图片的噪音。我们就是想利用神经网络,学习得出类似这样的核函数,进而获取有利于图像识别的特征(读者若还是不爽,可以参阅http://colah.github.io,此博客图文并茂,生动而详细地阐明了卷积)。
彩图卷积
上面交大的老师向我们展示了黑白图片卷积效果,然而现实的图片基本是彩色的,黑白时代早已不复存在。那么如何进行彩图卷积呢?且容我道来:首先,我们稍微科普一下图片处理的一些知识,我们知道,任何颜色都可以通过红绿蓝(RGB)这三种颜色合成,彩色图片就是通过RGB这三个通道合成的,且看https://en.wikipedia.org/wiki/Channel_(digital_image)上面的一张图片:
彩色图片就是这么得来的,现在,我们已经知道如何对一张黑白图片进行卷积,那么对于彩色图片,可以认为同时对三张灰色图片进行处理,那么一张灰色图片对应一个卷积核,此时的核应该为:
其中depth代表同时处理图片的个数,对于一张彩色图片,depth=3。
此时的图片:
而输出的卷积特征还是不变。且看我用代码说明:
width = 5 |
多核卷积
稍等一下,我们刚刚提到,不同的核函数可以学到不同的特征,那么求知若渴的我们肯定想来多几个核,学到更多不一样的特征。如何将上面讲到的单核卷积扩展到多个核呢,且看:
多个核的的核函数定义:
再扩展一维,马上搞定一切。而对应的输出卷积特征也会相应地扩展,还是代码比较容易说明:
width = 5 |
好了,卷积在我们这里不会再复杂下去了,我们以6重循环(虽然做法比较Naive,但是却能实实在在地掌握)揭开真实世界的卷积过程。
卷积网络中的卷积
理解了卷积的过程,理解卷积网络也就指日可待了。卷积网络其实和我们上节所讲述的前馈网络并无太大区别,只是将其中某些层换成了卷积层而已,所以卷积网络也是一种特殊的前馈网络。而卷积网络中的卷积层,就是一个多核卷积的过程的抽象。那么卷积网络最简单的结构是怎样的呢?又是怎样确定和学习到网络中的每一个未知参数呢?且听我娓娓道来。
卷积中超参数确定
到目前为止,前面所讲的,好多参数都没介绍是如何获得的,接下来,我一个一个讲清楚。首先,对于图片,这是输入,我们能做的只是对其进行扩大或缩小,而一般实践中,有时候我们会对图片进行zero-padding(边缘填充),就是在其外围进行一些补0操作,假如一张5X5的图片,我们对其zero-padding,那么它会变成7X7的图片,外围都是用0填充,为什么要进行zero-padding呢,一个是为了使图片的形状更方便我们进行卷积,另一个是因为它可以提高识别表现(详细原因请参考cs231n的课程)。由于zero-padding的存在,我们引入了hyper-parameter P。处理好输入后,我们第二个要确定的是核函数,基本上核的大小和个数都是我们人为指定的,也就是KernelSize还有KernelNum,此处我们又引入了两个hyper-parameter Ksize,Knum。那么决定好输入还有核函数之后,对于卷积,我们还会引入一个步长Stride的概念,我们上面介绍卷积的时候,默认Stride=1,也就是核每一次只会向右或向下移动一个像素点,为什么不能一次移动两个或三个像素点呢,于是Stride就应运而生了。此时引入第三个hyper-parameter S。行了,需要我们人为指定的参数就这么多。等一下,有些读者可能还会问,卷积后特征形状怎么确定呢,读者请拿起笔,在纸上验证验证一下下面这条公式,设,图片宽度为W,卷积核宽为F,步长S,zero-padding P,输出卷积特征的宽为H,则有:
也就是说卷积特征的大小是确定的,而卷积特征的个数和你选取的核函数个数是一样的。
Pooling过程
在卷积网络中,通常会引入一个操作,称为Pooling,在Yann Lecun的LeNet中使用的是mean pooling,但是后来研究卷积网络的人发现另外一种操作Max pooling更为有效,接下来,我们着重介绍Max Pooling。 此处我们再次借用ufldl中的一张动图:
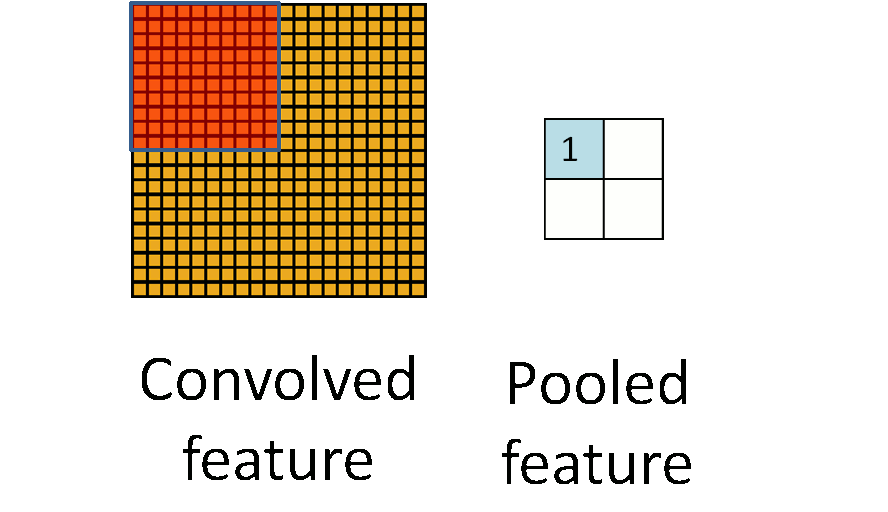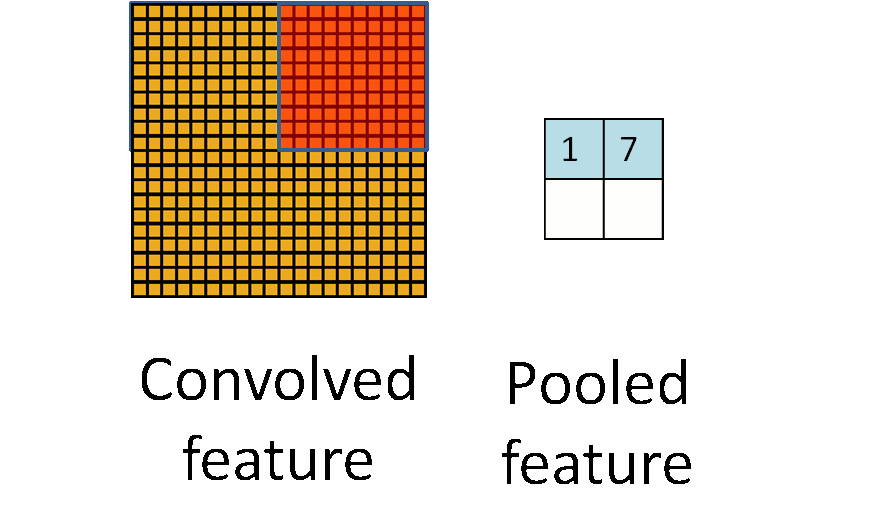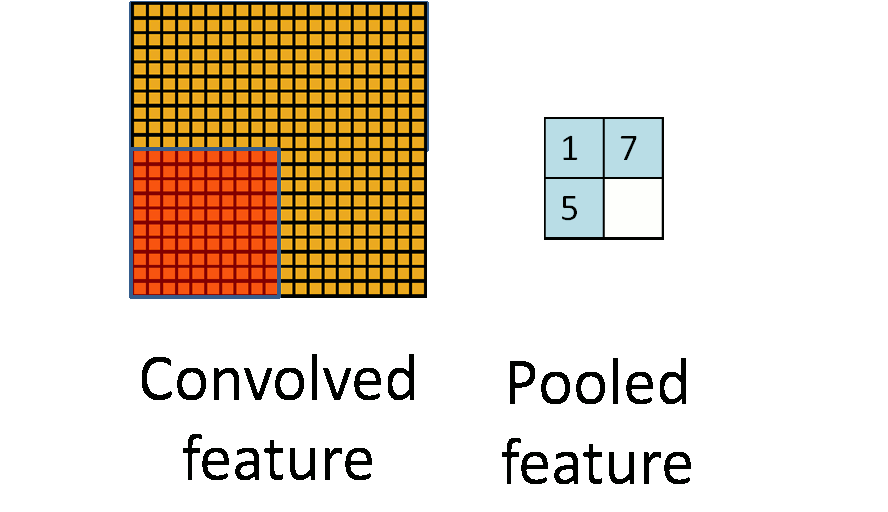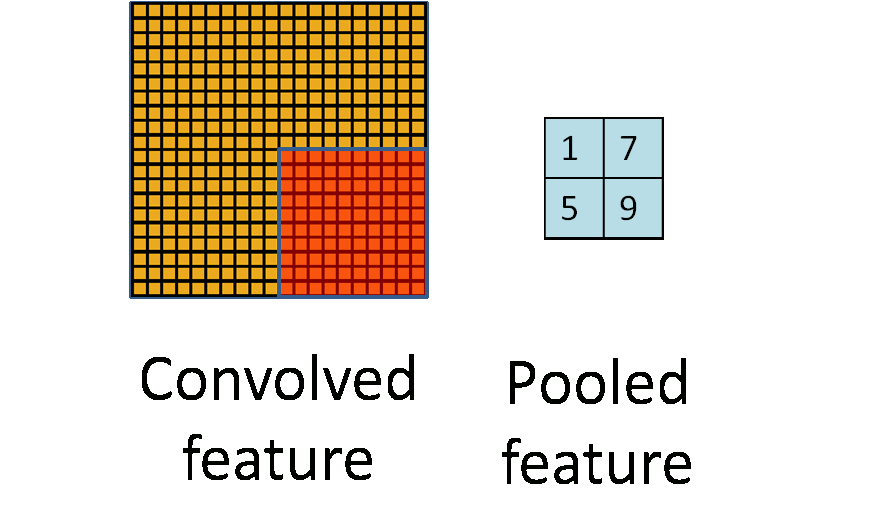
其中红色区域是pooling size,对于Max pooling,在红色方块每走一步,它都要进行一次pooling,也就是选取它自身区域下输出最大的值,作为下一个输出。这样说抽象了一点,幸好cs231n种有一张图片比较清晰反映这个过程: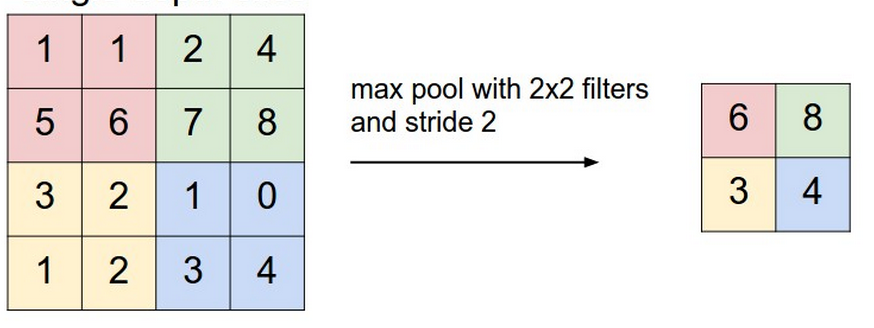
Pooling过程就是一个采样过程,这个过程可以起到一定的图像旋转不会影响识别的作用,想象一下,一张图片,你稍微旋转一些角度,它的Max pooling的值大致是不变的。再分析一下,经过max-pooling之后,输出应该是怎样的呢,一般max-pooling我们通常使用non-overlapping的方式,也就是如上图所示,各个pooling的方块之间是没有重叠的,那么对于2x2,步长为2的max-pooling,其输出将会将原始输入缩减为原来的1/4,且看代码:
#input = [8X8X5]的输入 |
卷积网络的架构部分我们已经学习了完毕了,通常一张图片会作为输入,然后经过conv卷积一下,再经过pooling层,然后又再次卷积,再pooling,知道设计者觉得到达合适程度后,再把输出作为我们上一节讲解的feedforward network的输入,再进行识别。
学习卷积网络中的参数
如何学习网络的参数呢,上一次,我们介绍了一种高效的学习方法,backpropagation,并且实践说明它确实是一种行之有效的方法。那么学习卷积网络的参数,没有别人,依旧是我们的老朋友,backprop。上一节中,我们的输入是一个向量,但是对于卷积网络,我们的输入是一个三维的输入,那么如何将backprop应用到卷积网络中呢?我们假定我们的网络是如下结构:
也就是“输入=>卷积=>pooling=>卷积=>pooling=>全连接=>全链接=>输出“这样的结构。注意,我们将非线性变换也抽象出一层并作为输出,此处我们利用了tanh变换。
注:最后一层直接用了激活函数tanh非线性变换。
非线性变换层中的backprop算法
与上一节的推导不同,我们的输出层是单独分离的一层变换,那么层第个神经元的输入是从FullCon层传来的输出,输出则是,那么输出与真实值产生的:
当执行backprop的时候,第个神经元将接收为:
然后向后传播乘上相应的导数:
对比一下上一节我们的推导:
我们很容易观察到抽象出一层的结果是将 $ 2*(tanh(s^L_j)-y_j)$)和 两部分乘积给分离开来了。这样将变换单独抽出一层的好处是,当你不想用激活函数变换而是想用或者 变换时,只需简单替换变换层即可,而不用改动其它层的代码。总而言之,因为这一层没有参数需要学习,所以非线性变换层的backprop过程就是将下一层传来的 不管三七二十一,乘上相应变换的导数,然后直接传播到上一层去。
Fullcon层的backprop算法
在上一节中,我们已经推导过,对于一个全连接网络,他的权重导数为:
而可以通过chain rule得出
所以FullCon层的各个权重的梯度我们可以不费力气求出。值得注意的是,上述推导的时候,同样因为变换被单独抽出一层,从而少了。我们知道网络的各个参数的梯度,均由相应可以推导得出,接下来我们将传播到上一层,也就是Pooling层,并试图求解其中参数的梯度。
Max Pooling中的backprop算法
max pooling层的backprop算是比较简单了,因为max-pooling的过程并没有参数要学习,它只需将下一层传来的传播到上一层就好。我们知道max-pooling的上一层就是卷积层,但是它们的形状却是不相同的,不能一对一地传播。那么该如何传播呢?此时我们需要一个upsample的过程,也就是将强行变成卷积层的形状。我们知道,maxpooling层的输出是上一层中poolsize区域中最大的那个值组成的,而其他都直接丢弃,那么传播的时候,最大那个值直接将传回去,其他的直接补0。所以我们在进行pooling的过程时,有必要记录此时取得最大值的坐标,方便upsample的过程。记录最大值的下标,我们只需在pooling代码中插入以下代码:
def max_pool(self,input,dIdx,hIdx,wIdx): |
其中:
self.poolIdx2MaxIdx[(wIdx,hIdx,dIdx)] = (w+i,h+j,dIdx) |
的作用就是记录最大值是来源于上一层输入的哪一个坐标,那么在进行backprop的时候,我们只需将传会这些坐标,其他位置补0即可,具体代码如下:
def back_prop(self): |
我们首先初始化上一层的delta并设置初始值为0,然后将该层的delta传回maxpooling时记录的位置。
卷积层的Backprop算法
卷积层的参数确定
首先,卷积网络有什么好处呢?上一节中我们已经介绍了前馈网络,而且它可以在Mnist上得到不错的结果,那么我们发明卷积网络到底有什么好处呢?我们回顾一下历史,卷积网络其实也并非凭空捏造出来的,和上一节介绍神经网络的时候一样,又是生物学家的研究给来的灵感,一个叫Hubel的生物学家,在研究猫的视觉的时候,发现了一个receptive field(感受野)这样的概念。也就是生物大脑在处理视觉的时候,是由很多receptive field在进行处理加工的,然后再传播开去。而大致过程就是我们的利用核进行卷积的过程类似,才因此发明了卷积神经网络。机器学习中,一个最大的敌人就是Overfitting(过拟合),我们上一节所介绍的网络,对于高清无码的大图片,需要学习的参数太多,很容易就导致overfitting,举个例子,我们来算一笔账:对于一张100x100的图片,接入一个拥有100个神经元的layer,再输出到一个有10个神经元的output,那么,其需要学习的参数有:
一百多万个参数,这还不是高清无码的图片,这么多参数,使得网络非常容易出现overfitting,至于原因,讲清楚超出了本节的范围,读者可以自行上网查找资料,或者上上Ng的cs229的课程,自然明白。
那么卷积网络需要学习多少参数呢?
首先,我们利用核进行卷积操作,每个核对于输入都不是全连接的,而是局部连接,也就是每个核都只是和输入的一部分连接(因为核通常都是比输入小很多),我们来算一下账,还是用上面的例子,我们的选一个核,大小为5x5,步长为1,经过卷积后,输入层和卷积层之间需要学习的参数为:
要学习的参数还是太多,但是计算机学者总会有办法的,他们通过提出一个假设,然后提出weight-sharing这种办法。也就是对于locally connect的核,限制他们的边权重必须一样,以下是这种假设的英文原文:
If detecting a horizontal edge is important at some location in the image, it should intuitively be useful at some other location as well due to the translationally-invariant structure of images。
且看下图,来自Hinton老爷子在Coursera课程上的截图:
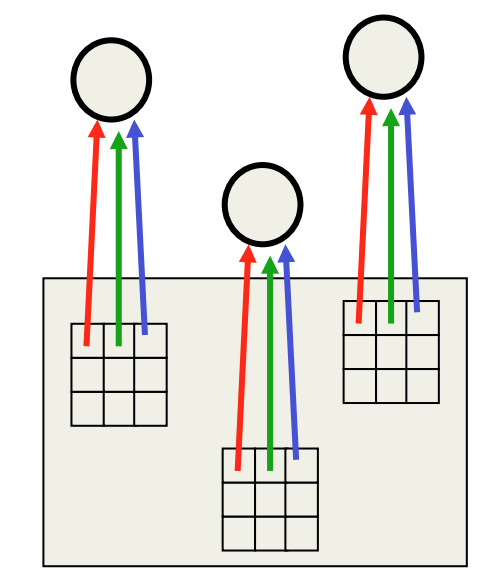
图中,输入是一张图片,而卷积核有3个,每个卷积核通过局部连接9个输入,此时需要学习的参数有Nx9个(N是卷积特征的个数),但是通过weight-sharing这个条件,图中红色边的权重都必须是一样的,蓝色边也是如此,所以需要学习的参数就变为只是卷积核的大小,也就是9个而已。
有了这个假设,输入层到卷积层之间需要学习的参数变为:
5x5+1 = 26 (1代表bias项,上一节已经讲过)
此时我们再加多几个核,就是用10个核去卷积图片,输入和卷积之间需要学习的参数为:
经过卷积后,得到的卷积特征有96x96x10。此时我们再进行一个2x2,步长为2的maxpooling操作,特征就变为:48x48x10,再经过16个5x5的卷积核步长为1的卷积层,此时需要学习的参数为:
此时输出特征为:44x44x16,再经过pooling,输出特征变为:
此时再连接到有100个神经元的隐藏层,需要学习的参数为:
加上输出层和隐藏层之间的参数:
所以,总体的学习参数为:
这就是卷积网络自身自带的regularization的作用。
学习卷积层参数
对于卷积层中的任意一个权重:
注意 正是我们卷积权重的shape。
我们应该如何求得?
回忆一下,对于常规的多层前馈网络,我们是根据以下式子求出权重梯度的:
我们知道,梯度应该等于乘上它当前层与对应的输入,读者请拿起笔,画画对于二维的卷积网络,对于核里面一个权重,当前层中输入有多少个地方和该权重相乘过,如果你照做了,下面结论就不会难得出:
代码实现上述:
def compute_single_w_grad(self,wIdx,hIdx,dIdx,num): |
好了,解决了如何求取卷积层权重的梯度,接下来我们要推导如何将卷积层的传播给上一层。
首先我们还是回忆一下,普通前馈网络中,是如何求得的,看回上一篇,我们可以知道(因为我们单独将tanh抽出一层,所以相比上一节的介绍,会少了一个)_:
也就是,求取可以分为两部分,一部分是求取下一层和所在那一层的权重的点积。那么在卷积网络中,对于一个,假设第层中,核的个数为,层中权重的宽为,高为,而卷积步长为,那么我们可以以如下式子求出:
其中限制条件有(假设的宽为,高为):
利用代码实现上述,且看:
def propagate_delta(self): |
这是本篇中最为triky的部分,需要读者静下心,用纸画出卷积层与上一层的关系,然后再慢慢推出,也花了我不少时间,期间还推错了几次,幸好后来用gradient check慢慢发现错误,并推导正确的。
卷积网络的代码设计
很不错,至此我们已经推出了卷积网络的训练过程和应用过程,虽然代码没有经过优化,但是是最原生也是最直接的推导,并没有加入太多的tricks,个人认为比较容易理解,最后,我们来讲讲卷积网络的代码实现过程,首先,在讲解原理的时候,我们对于网络结构给出了一种分层结构,分别分为卷积层,pooling层,全连接层,还有激活层。那么代码实现时,很显然可以利用面向对象机制,将所有层抽象一个基础层Layer,对于Layer的接口,应该有如下实现:
def __init__(self,preLayer,width,height,depth): |
除了必须有前向和后向两个方法,我还而外抽出了更新权重的方法,在构造的时候,必须传入该层上一层的引用,以便于backprop的操作。将激活层单独抽出,是方便于更换激活函数,使得更换的时候只需修改配置,而不用修改代码,网络最终再根据配置搭建构造任意网络模型,其用法是
config = [ |
这样的可插拔方式使得变换网络非常自由,可以轻松更替激活层,调整参数。当然网络的卷积实现和backprop实现都是极其Naive的,导致训练起来非常慢,基本上只能作为toy实现,当然本文的目的只是为了带领初学者认识卷积网络,所以这样的toy实现也足够了。对于那些不满足的读者,请参考论文《High Performance Convolutional Neural Networks for Document Processing》。里面有介绍如何将卷积过程化为矩阵相乘,进而可以利用BLAS或者GPU进行高效实现。
当然实现一个toy卷积网络也并非轻松,你要实现好一个准确的gradient check程序,对于每一层的实现,先用人为数据进行测试,再进行gradient check,对于tanh变换,analytic gradient的数值和 numerical gradient的数值的相对误差最好在1-e6左右,当你将所有层都通过gradient check之后,再在一份小的数据上进行训练,人为使网络overfitting,如果会overfitting,恭喜你,你的网络实现大概是没什么问题了。每一个训练pass,都可以打印相应的cost,进而进行分析。
我利用实现好的卷积网络,取Mninst的训练数据1000份进行训练,取测试数据2000份进行测试,训练次数相同,结果都表明,普通前馈网络很容易就overfitting,而卷积网络则不会,并且测试结果都是卷积网络略胜一筹,当然卷积网络的训练时间是普通网络训练时间的上百倍。
当实现完卷积网络后,我还是挺高兴的,从头到尾,翻阅资料,理解原理并实现,排除bug,过程艰辛,比如当网络gradient check有误差时,我都很难确定是gradient check的程序出了问题还是网络实现出了问题,怪只怪工程实现能力还比较弱,总之,理解实现卷积网络,又为我揭开计算机科学的一个面纱,值得庆祝。
完整代码请戳:https://gitee.com/Carl-Xie/NN-Toys/blob/master/ConvNetwork.py
参考引用
cs231n:http://cs231n.github.io/
ufldl:http://ufldl.stanford.edu/
网络书籍:http://neuralnetworksanddeeplearning.com/
论文:http://cogprints.org/5869/1/cnn_tutorial.pdf
外国blog:
http://deeplearning.net/tutorial/lenet.html
http://andrew.gibiansky.com/blog/machine-learning/convolutional-neural-networks/


