Python基础语法(六)数据序列——字符串
目标
- 认识字符串
- 下标
- 切片
- 常用操作方法
认识字符串
字符串是 Python 中最常用的数据类型。我们一般使用引号来创建字符串。创建字符串很简单,只要为变量分配一个值即可。
a = 'hello world' |
注意:控制台显示结果为
<class 'str'>, 即数据类型为str(字符串)。
字符串特征
-
一对单引号或双引号(一引号)字符串
name1 = 'Tom' |
-
三对单引号或双引号(三引号)字符串
name3 = ''' Tom ''' |
注意:三引号形式的字符串支持换行。
思考:如果创建一个字符串
I'm Tom?
c = "I'm Tom" |
字符串输出
print('hello world') # 直接输出 |
字符串输入
在Python中,使用==input()接收用户输入。==
-
代码
name = input('请输入您的名字:') |
-
输出结果

下标
“下标”又叫“索引”,就是编号。比如火车座位号,座位号的作用:按照编号快速找到对应的座位。同理,下标的作用即是通过下标快速找到对应的数据。
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号[]来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标] |
不包含尾下标对应的数据, 正负整数均可
索引值以 0 为开始值,-1 为从末尾的开始位置。

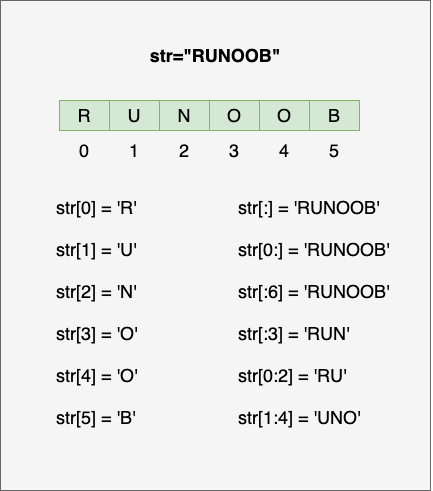
示例
需求:字符串name = "abcdef",取到不同下标对应的数据。
-
代码
name = "abcdef" |
-
输出结果

注意:下标从0开始。

切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
语法
序列[开始位置下标:结束位置下标:步长] |
注意
- 不包含结束位置下标对应的数据(相当于左闭右开), 正负整数均可;
- 步长是选取间隔,正负整数均可,默认步长为1。
- 若步长为负数,表示倒序排列选取.
示例(仔细体会字符串切片语法含义)
str1 = '0123456789' |
常用操作方法
字符串的常用操作方法有查找、修改和判断三大类。
查找
所谓字符串查找方法即是查找子串在字符串中的位置或出现的次数。
-
find():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1。
-
语法
字符串序列(或序列名).find(子串, 开始位置下标, 结束位置下标) |
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找。
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
-
index():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则报异常。
-
语法
字符串序列(或序列名).index(子串, 开始位置下标, 结束位置下标) |
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找。
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
-
rfind(): 和find()功能相同,但查找方向为右侧开始。
-
rindex():和index()功能相同,但查找方向为右侧开始。
-
count():返回某个子串在字符串中出现的次数
-
语法
字符串序列(或序列名).count(子串, 开始位置下标, 结束位置下标) |
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找。
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
修改
所谓修改字符串,指的就是通过函数的形式修改字符串中的数据。
常用(重点)
-
replace():替换
-
语法
字符串序列(或序列名).replace(旧子串, 新子串, 替换次数) |
注意:替换次数如果查出子串出现次数,则替换次数为该子串出现次数。
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
注意:数据按照是否能直接修改分为可变类型和不可变类型两种。字符串类型的数据修改的时候不能改变原有字符串,属于不能直接修改数据的类型即是不可变类型(相当于C语法中的”形参“)。
-
split():按照指定字符分割字符串。
-
语法
字符串序列(或序列名).split(分割字符, num) |
注意:num表示的是分割字符出现的次数,即将来返回数据个数为num+1个。
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
注意:如果分割字符是原有字符串中的子串,分割后则丢失该子串。
-
join():用一个字符或子串合并字符串,即是将多个字符串合并为一个新的字符串。
-
语法
字符或子串.join(多字符串组成的序列) |
-
快速体验
list1 = ['chuan', 'zhi', 'bo', 'ke'] |
大小写转换
-
capitalize():将字符串第一个字符(首字母)转换成大写。
mystr = "hello world and itcast and itheima and Python" |
注意:capitalize()函数转换后,只字符串第一个字符大写,其他的字符全都小写。
-
title():将字符串每个单词首字母转换成大写。
mystr = "hello world and itcast and itheima and Python" |
-
lower():将字符串中大写转小写。
mystr = "hello world and itcast and itheima and Python" |
-
upper():将字符串中小写转大写。
mystr = "hello world and itcast and itheima and Python" |
删除空白字符
-
lstrip():删除字符串左侧空白字符。
mystr = " hello world and itcast and itheima and Python " |

-
rstrip():删除字符串右侧空白字符。
mystr = " hello world and itcast and itheima and Python " |

-
strip():删除字符串两侧空白字符。
mystr = " hello world and itcast and itheima and Python " |

字符串对齐
-
ljust():返回一个原字符串左对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串。
-
语法
字符串序列.ljust(长度, 填充字符) |
-
输出效果

-
rjust():返回一个原字符串右对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同。
-
center():返回一个原字符串居中对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同。

判断
所谓判断即是判断真假,返回的结果是布尔型数据类型:True 或 False。
判断是否以子串开头或结尾
-
startswith():检查字符串是否是以指定子串开头,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
-
语法
字符串序列.startswith(子串, 开始位置下标, 结束位置下标) |
-
快速体验
mystr = "hello world and itcast and itheima and Python " |
-
endswith()::检查字符串是否是以指定子串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
-
语法
字符串序列.endswith(子串, 开始位置下标, 结束位置下标) |
-
快速体验
mystr = "hello world and itcast and itheima and Python" |
判断字符串是否包含字符或数字等
-
isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False。
mystr1 = 'hello' |
-
isdigit():如果字符串只包含数字则返回 True 否则返回 False。
mystr1 = 'aaa12345' |
-
isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False。
isalnum():数字或字母或组合
mystr1 = 'aaa12345' |
-
isspace():如果字符串中只包含空白,则返回 True,否则返回 False。
mystr1 = '1 2 3 4 5' |
Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
\(在行尾时) |
续行符 | 源程序:print("line1 \ ... line2 \ ... line3") 输出: line1 line2 line3 |
\\ |
反斜杠符号 | 源程序:print("\\") 输出: \ |
' |
单引号 | 源程序: print(''') 输出: ' |
" |
双引号 | 源程序:print(" " ") 输出: " |
\a |
响铃 | 源程序:print("\a")输出:执行后电脑有响声。 |
\b |
退格(Backspace) | 源程序:print("Hello \b World!") 输出: Hello World! |
\000 |
空 | 源程序:>>> print("\000") 输出: |
\n |
换行 | 源程序:>>> print("\n") 输出: |
\v |
纵向制表符 | 源程序:>>> print("Hello \v World!") 输出: Hello World! |
\t |
横向制表符 | 源程序:print("Hello \t World!") 输出: Hello World! |
\r |
回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | 源程序:print('google runoob taobao \r 123456')) 输出: 123456 runoob taobao |
\f |
换页 | 源程序:print("Hello \f World!") 输出: Hello World! |
\yyy |
八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | 源程序:print("\110\145\154\154\157\40\127\157\162\154\144\41") 输出:Hello World! |
\xyy |
十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | 源程序:print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21" 输出:Hello World! |
\other |
其它的字符以普通格式输出 |
使用 \r 实现百分比进度:
import time |
示例
print('\'Hello, world!\'') # 输出:'Hello, world!' |
Python 字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看前面章节关于格式化字符串内容。 |
示例
a = "Hello" |
输出结果:
a + b 输出结果: HelloPython |
总结
-
下标
- 计算机为数据序列中每个元素分配的从0开始的编号
-
切片
序列名[开始位置下标:结束位置下标:步长] |
-
常用操作方法
- find()
- index()